Teoretické a praktické aspekty získávání informací
z internetových portálů
© 2012 Ing. Roman Fischer
Úvod
Získávání informací z informačních portálů, katalogů, e-shopů, jejich stránek a dokumentů přístupných prostřednictvím sítě Internet je v současné době velmi rychlý a efektivní způsob vytváření databází informací, které lze následně využít v mnoha různých směrech. Nejedná se jen o vytváření srovnávacích katalogů zboží, jak jsou zpravidla známy běžnému uživateli, nebo využití jako mocné nástroje marketingu, kdy jsou potřebná data získávána ze sociálních sítí, ale také o cílené získávání znalostí z konkrétních oborů podle předem určených klíčových slov. Na rozdíl od prvně jmenovaných, kdy je primárním zájmem poskytnout určitou službu (např. srovnávat ceny produktů v elektronických obchodech) jsou posledně jmenované zaměřeny na firemní zákazníky, kteří pomocí monitorování konkurence, vývoje ve vědě a technice, ale i sledováním činností státní správy uveřejňované na Internetu získávají výhody v hospodářské soutěži. Příkladem může bát sledování nabídek realitních kanceláří, získávání dat o jejich nabídkách a vytváření nových realitních portálů bez nutnosti navazování spolupráce s individuálními subjekty na realitním trhu nebo naopak snadný způsob zjišťování situace na realitním trhu pro uspokojování poptávky po nemovitosti pro koncové subjekty.
V následujícím textu se zaměřím na dva samostatné aspekty získávání informací z internetových portálů. V první části analyzuji technické metody sběru informací z internetových stránek a ukážu základní metody pro jejich interpretaci a klasifikaci. V druhé části se budu věnovat praktickému využití takto sbíraných dat a představím některé nástroje a služby, které lze pro tento účel využít.
Metody sběru dat z internetových stránek
„Nejčastěji probíhá sběr dat kombinací extrakce dat, fuzzy logiky a lidské práce.“ [1]
Nejjednodušší způsob je předávání dat mezi stranami definovaným způsobem. V takovém případě však musí strana sbírající data znát strukturu sbíraných dat. Dochází k tomu zpravidla tam, kde jsou data vystavena již strukturovaně, např. v XML formátu, a existuje k nim dostupný popis této struktury.
Další využívanou možností je procházení celého webu (nebo definovaných adres) a čtení jejich obsahu. Zde ovšem narážíme na problém struktury získaných dat. Každý webový portál, internetový obchod nebo dokument umístěný na webu obsahuje jiné informace a má odlišnou strukturu.
Tento způsob sběru dat je v současnosti zabezpečován dvěma způsoby. Buď klasickým čtením obsahu internetových stránek a dokumentů, tzv. „crowling" nebo získáváním dat od samotných uživatelů, tzv. „crowdsourcing“ a jejich následným zpracováním.
Crowling
„Crowling“ nebo také „spidering“ je technika nejčastěji používaná vyhledávacími roboty, které stahují obsah internetových stránek, ukládají ho do lokální databáze, kde je následně klasifikován a indexován pro pozdější jednodušší a rychlejší vyhledávání relevantních informací. [2] Nastává ale problém, jak nejefektivněji procházet internetový obsah a zaručit jeho rychlé čtení, aniž by se automatický robot zacyklil nebo zpomalil v kombinaci odkazů vedoucích ke stejnému obsahu. „Vzhledem k tomu, že šířka pásma internetového připojení není nekonečná, ani zdarma, stává se pro procházení webu zásadní najít nejen škálovatelný, ale i účinným způsob, má-li být zaručeno rozumné měřítko kvality a čerstvosti získaných dat." [4] Program sbírající data musí na každém kroku pečlivě vybrat, které stránky navštíví jako další.
Chování programu sbírajícího data je výsledkem kombinace následujících postupů:
- „politika výběru, která určuje, které stránky stáhnout,
- politika opětovné návštěvy, která určuje, kdy se vrátit pro aktuální verzi stránky,
- politika zdvořilosti, která určuje, jak se vyhnout přetěžování čtených stránek a
- politika paralelního zpracování, která koordinuje distribuované prohledávače.“ [5]
Politika výběru
Jak jsem citoval výše, pro vyhledávací roboty je zásadní, které stránky a dokumenty stahovat a indexovat, a které mají vynechat. Studie z roku 2005 uvádí, že i vyhledávače s širokou působností indexují jen 40-70% webových stránek. [4]
Je zřejmé, že pro správnou politiku výběru obsahu, který má být stažen a klasifikován a indexován, musí být zavedena metrika, kterou bude řazen. Významnost obsahu je většinou určena počtem na něj vedoucích odkazů, jeho návštěv a jeho URL, která je zvlášť důležitá pro vyhledávače zaměřující se na konkrétní druh obsahu nebo konkrétní domény či stránky (tzv. vertikální vyhledávače). Nejčastějšími metodami jsou nejkratší cesta v grafu (struktuře webu), zpětné odkazy a PageRank.
Nejkratší cesta v grafu postupně projde všechny možnosti cest mezi každými dvěma uzly (odkazovanými stránkami) a pokud zjistí, že cesta přes uzel (stránku) by byla kratší, použije ji. „Velkým problémem tohoto algoritmu je ovšem jeho výpočetní složitost - s tím, jak roste počet vrcholů, mezi kterými vzdálenost počítáme, roste počet kroků algoritmu podobně jako graf funkce y = x3.“ [5] Tato metoda je využívána pro nalezení nejkratší cesty k dané stránce.
Metoda zpětných odkazů se zase používá k určení, kolik odkazů směřuje na definovanou stránku. Čím více odkazů, tím je stránka považována za důležitější.
PageRank, vyvinutý na Stanfordské univerzitě a na základě výhradní licence využívaný vyhledávačem Google, přidává k počtu zpětných odkazů navíc váhu významnosti samotné stránky, čímž zajišťuje, že zpětné odkazy nejsou jediným měřítkem významu. Ve výsledku má tento algoritmus efekt takový, že i stránka s více zpětnými odkazy může být hodnocena jako méně významná než stránka, na kterou vede méně odkazů, ale zato z významnějších stránek.
Politika opětovné návštěvy
Pro zajištění časové efektivnosti sběru dat je samozřejmě velmi významným faktorem určení, zda má robot stránku, kterou má již staženou a uloženou, opět navštívit či nikoliv. Obsah na Internetu se mění v různých časových intervalech a je jasné, že z hlediska nákladů a času je nemožné celý web, ale i konkrétní cílený obsah, stahovat a ukládat pokaždé znovu. K stanovení, zda stránku stáhnout nebo ne jsou zpravidla používány funkce aktuálnosti (Freshness) a stáří (Age). [6]
Obě funkce lze ji vyjádřit následovně: [7]
Aktuálnostje funkcí data poslední změny t stránky p oproti datu stránky v databázi vyhledávače.
![]()
Stáří stránky p v databázi vyhledávače v čase t je vyjádřena funkcí:
![]()
Politika zdvořilosti
Ani při rychlých datových spojích a velkých šířkách pásma, které servery využívají je nelze zatěžovat nadbytečnými, příliš často se opakujícími dotazy, protože by to vedlo jen k tomu, že se budou jejich provozovatelé bránit a zabezpečí své prostředky proti přístupu nadměrně vytěžujících vyhledávacích robotů.
Jak uvedl Martijn Koster, vývojář často citovaný na Wikipedii, hlavní oblasti, kde sběrače obsahu způsobují problémy, jsou:
- „síťové zdroje, protože prohledávače vyžadují značnou šířku pásma a operují na vysokém stupni paralelního přístupu po dlouhou dobu,
- přetížení serverů, hlavně tehdy, když mají příliš velkou četnost přístupu,
- špatně napsané sběrače, které dokážou způsobit výpadek serveru nebo ty, které stahují stránky, které neumějí zpracovat,
- soukromé sběrače dat, pokud jsou nasazeny příliš mnoha uživateli, mohou způsobit narušení sítí nebo webových serverů.“ [8]
Velké komerční sběrače dat zachovávají odstup zpravidla mezi 20 sekundami a 3-4 minutami.
Na následujících dvou obrázcích jsou znázorněny analýzy log-souborů dvou webových serverů pomocí statistik AWStats. První patří elektronickému obchodu s 20 tisíc návštěvníky měsíčně, druhý pak k běžné firemní internetové prezentaci s návštěvností kolem 1000 návštěv měsíčně. Vidíme, že nejvyšší četnost přístupů vykazuje Googlebot, který v obou případech jednoznačně vede, ale zároveň také dojdeme k závěru, že i pro něj jsou oba weby různě důležité, což značí až 20x větší četnost návštěv na eshopu oproti firemní prezentaci.
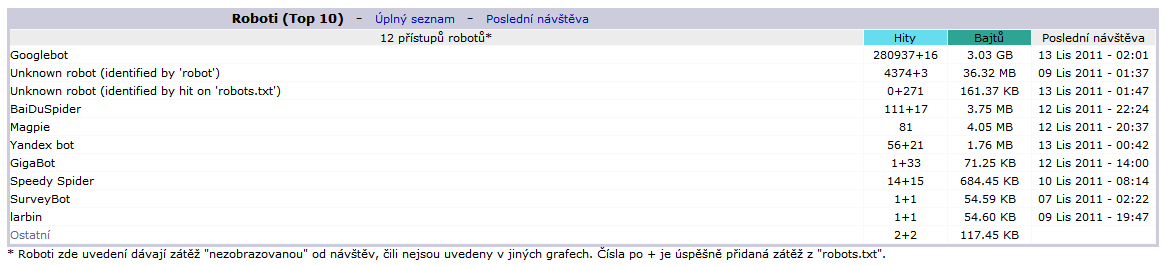
Obr. 1 - Návštěvnost robotů na webu internetového obchodu
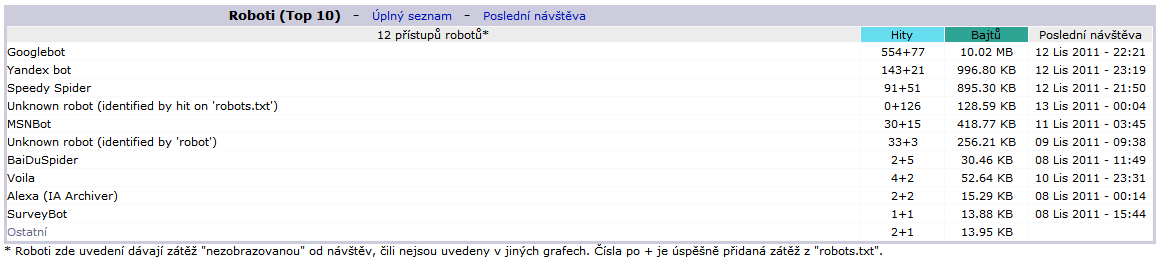
Obr. 2 - Návštěvnost robotů na webu běžné firemní prezentace
K definici, které zdroje mohou být stahovány a indexovány sběrači dat používají webový vývojáři a administrátoři tzv. Robots Exclusion Protocol, známý také jako Robots.txt určující, které adresáře nebo dokumenty jsou pro vyhledávač přístupné a které nikoliv. Lze v něm definovat, které vyhledávače mohou k místním prostředkům přistupovat, které naopak nesmějí, kam až mohou v adresářové struktuře jít a pro některé vyhledávače lze určit i časový interval opakování přístupu.
Politika paralelního zpracování
V případě, kdy je pro sběr dat nasazena distribuovaná aplikace, která dokáže v daném čase zpracovat více zdrojů, je nutné řešit, jak zamezit paralelním nebo opakujícím se přístupům ke stejnému zdroji.
Řešení tohoto problému jsou v současnosti popsány dvě. Buď je využíván tzv. dynamický způsob přidělování adres, kdy existuje centrální server, který jednotlivým sběračům dat přiděluje adresy a řídí jejich vytížení včetně možnosti zastavit celý proces stahování dané adresy.
Druhou možností je statické přiřazení. V tomto případě je z URL pomocí hash funkce vytvořeno číslo, které odpovídá indexu příslušného procesu sběru dat.
Podle [10] musí statické přidělování mí následující základní vlastnosti, aby bylo efektivní:
- každý proces sběru dat by měl mít přibližně stejný počet počítačů,
- roste-li počet procesů sběru dat, musí se zmenšovat počet cílů, ze kterých procesy sbírají data a
- přiřazování musí být schopno přidávat a odebírat procesy dynamicky.
Crowdsourcing
Princip tohoto způsobu tkví v tom, že zapojuje samotného uživatele. Pro získávání dat je potřeba zainteresovat návštěvníky webových portálů, aby sami sbírali a předávali informace, které při procházení webu zjistí. Výhodou jsou nižší počáteční náklady, není potřeba komplikovaně analyzovat sesbíraná data pomocí pravděpodobnostních počtů, ovšem na druhé straně kvalita takto získaných dat může být nižší, než při výše popsaném crowlingu. Nelze však tvrdit, že tato technika nevyžaduje žádné dodatečné automatické ani lidské zpracování dat. I data získaná od uživatelů, i přes různé bezpečnostní politiky zabezpečující jednotnost vstup, budou nekonzistentní a mnohdy se nevyhneme ani opravě dat lidskými zdroji.
Technika crowdsourcing není žádným nováčkem. V oblasti IT byla definována sice až v roce 2006 Jeffem Howem [11], ale byla využívána už mnohem dříve. Například Oxford English Dictionary byl v 19. století sestaven mimo jiné z mnoha milionů příspěvků veřejnosti nebo známá internetová encyklopedie Wikipedia je plněna a spravována z převážné části uživateli internetu.
Termín Crowdsourcing se stal populární především díky hromadné spolupráci uživatelů pomocí technologií, které přinesl Web 2.0. Přes nesporné výhody má však i své odpůrce.
Výhody crowdsourcingu podle [11]:
- problémy lze řešit s poměrně nízkými náklady,
- platí se za výsledek a někdy ani to ne,
- organizace dokáže zachytit větší množství talentů, než může mít sama k dispozici,
- nasloucháním široké mase lidí může organizace získat z první ruky informace o svých zákaznících,
- spolupracující společenství cítí spolupodílnictví na budované značce, což samo může být dostatečnou odměnou za spolupráci.
- Paradoxně spoluzakladatel Wikipedie Jimmy Wales uvádí následující důvody kontroverznosti této metody.
- „Dodatečné náklady pro dotažení crowdsourcing projektu do akceptovatelného závěru,
- větší pravděpodobnost, že se projekt nezdaří díky nedostatku aktuální motivace, malému počtu účastníků, nízké úrovni kvality odváděné práce, nedostatku osobního zájmu o projekt, globálním jazykovým bariérám nebo díky obtížnosti vést crowdsourcingový projekt,
- mzdy pod tržní úrovní nebo neexistence mzdy; výměnné obchody, které zhoršují kvalitu získaných dat,
- žádné písemné smlouvy, dohody o neposkytování informací nebo zaměstnanecké smlouvy,
- problémy ve spolupráci členů projektu, hlavně při konkurenčních projektech,
- citlivost na chybu v případě cílených útoků na práci v projektu.“ [12]
V oblasti získávání informací z webových portálů ale mohou být tyto projekty velmi užitečné, zvláště pak proto, že „živý“ uživatel se mnohdy dostane tam, kam robot nemůže nebo sám dokáže provést prvotní analýzu obsahu webové stránky a najít požadovanou informaci. Jak jsem uvedl výše, tyto přínosy nám pomáhají od nákladů, které by jinak musely být vynaloženy na sofistikované algoritmy, vyhledávající požadované informace v komplikovaných, tematických, např. vědeckých zdrojích dat.
V praxi však dochází ke kombinaci crowlingu a crowdsourcingu. V oblastech, kde lze nasadit robota jsou data ve velkých objemech a relativně krátkém čase automaticky zpracována, v oblastech, kde je vhodnější lidská součinnost, je sběr dat ponechán komunitám nebo jiným zainteresovaným skupinám.
Příkladem může být kanadský portál Wishabi zaměřující se na srovnávání cen a sociální marketing. Nejen že sbírá data z maloobchodních portálů, informuje o cenovém vývoji, dokáže své uživatele informovat o změnách cen nebo nabízí přeshraniční obchod (nákupy v eshopech z USA zasílané do Kanady), ale využívá i sociální sítě k agregaci poptávky. Zatímco prvně jmenované jsou jasně založeny na automatickém pravidelném sběru dat, jejich kategorizaci a následném předávání uživatelům, posledně jmenovaná aktivita získává data od samotných uživatelů. Tento zajímavý způsob marketingu spočívá v tom, že uživatelé Facebooku se mohou pomocí svých přihlašovacích údajů zaregistrovat do portálu Wishabi, který následně sbírá jejich požadavky po konkrétním produktu, které uveřejňují na svém Facebookovém profilu. Pokud jejich přátelé na Facebooku následují jejich poptávku a přidávají se k požadovanému produktu, jsou všechny jejich individuální poptávky na portálu Wishabi agregovány a nabízeny prodejcům, kteří je mohou přesně a cíleně uspokojovat. Jedná se vlastně o podobný model jako u kolektivního nakupování s tím rozdílem, že nejprve vzniká poptávka a až poté vzniká adekvátní nabídka.
Metody pro interpretaci a klasifikaci získaných dat
V předchozím textu jsem vysvětlil způsoby získávání dat a výhody i úskalí jejich použití. Vytvořením báze sesbíraných dat ale teprve začíná ta nejdůležitější část. Nyní je potřeba data interpretovat a klasifikovat, aby mohla být efektivně použita. Z dat je potřeba obdržet informaci.
Jak jsem zmínil již na začátku, nejčastějšími způsoby interpretace jsou pravděpodobnostní matematika, hlavně fuzzy logika a lidská práce zpracovávající data na základě velkého množství pravidel s pomocí mnoha různých statistických metod. Čím komplexnější informace chceme získat, čím rozsáhlejší zaměření internetových portálů zkoumáme, tím více bude pravidel. Nemá smysl zde rozebírat principy fuzzy logiky nebo pravděpodobnostního počtu. Zaměřím se spíše na popis příkladu, který interpretaci dat vhodně ilustruje.
Klasifikace obrázků
V následujícím textu předvedu způsob, kterým lze ze získaných dat klasifikovat obrázky a tyto pak rozdělit do skupin podle toho, zda se jedná o reálný obrázek nebo text. Pro menší matematickou náročnost se omezím jen na obrázky ve stupních šedi.
Prvotní klasifikaci bude potřeba provést již při sbírání dat. Jelikož jsou obrázky na webových stránkách jasně definovány pomocí HTML značky <img> není problém je ihned zařadit do samostatné kategorie.
Nyní máme v databázi uložené soubory, o kterých víme, že jsou obrázky. Nyní se je budeme snažit rozdělit do dvou výše zmíněných skupin. Jako pravidlo, podle kterého budeme obrázky rozdělovat, použijeme statistickou funkci entropie. „Entropie je v teorii informace míra nejistoty spojené s náhodnou veličinou. Entropie kvantifikuje očekávané hodnoty informace obsažené v určité zprávě, zpravidla v jednotkách jako jsou bity. Zprávou rozumíme specifický výskyt náhodné veličiny.“ [13]
Pro jednotlivé obrázky budeme tedy určovat, zda se v uspořádání jejich pixelů nachází určité zákonitosti nebo zda se jedná spíše o náhodné uspořádání. Vycházíme z předpokladu, že soubory, u kterých budou pixely zcela náhodně uspořádány, představují obrázek. Soubory, jejichž pixely vykazují určitou míru pravidelnosti, považujeme za text.
Každý obrázek ve stupních šedi se skládá z daného množství čtvercových polí (pixelů) a každý z nich nese informaci o míře zatmavění daného pole. Čím je hodnota v poli větší, tím je bod tmavší. Výsledný obraz se skládá z velkého množství těchto polí a lidské oko je vnímá jako celek. Čím více polí obrázek obsahuje, tím vyšší je jeho rozlišení a tím jemnější je pro lidské oko výsledný obraz.
| 40 | 30 | 20 | 40 |
| 20 | 20 | 20 | 20 |
| 40 | 20 | 20 | 20 |
| 40 | 40 | 40 | 30 |
Obr. 3 – Část digitálního obrázku ve stupních šedi. Každé pole nese informaci o míře své tmavosti.
Každý obrázek ve stupních šedí je tedy matice. Při ukládání můžeme každý prvek matice uložit buď jako jediný bit nebo jako byte, tedy 8 bitů. Je zřejmé, že při ukládání polí jako bity lze dosáhnout jen uložení monochromatického obrázku, protože každé pole může obsahovat jen 0 nebo 1. Uložení v bytech však rozšiřuje kapacitu na 28 bitů, tedy 256 možných hodnot. V tom případě pak můžeme obrázek uložit v 256 stupních šedi.
Statistickou veličinu entropii, vycházející z fyzikálních zákonů termodynamiky, vyjadřujeme vzorcem:
![]()
Pi je pravděpodobnost výskytu hodnoty x stupně šedi (světlosti) v matici obrázku. „Ze statistického hlediska mají tyto hodnoty normální rozdělení a jsou obecně známé jako histogram.“ [15] Výpočet hodnot histogramu zde nechávám pro usnadnění stranou, nehledě na to, že jej dokáže spočítat každý triviální grafický prohlížeč.
Získáme-li z hodnot histogramu hodnotu entropie, můžeme již lehce dělit zkoumané obrázky do skupin. „Čím vyšší bude hodnota entropie, tím více jsou závislé pravděpodobnosti výskytu stejných hodnot x stupně šedi (světlosti).“ [14] Tím pravděpodobněji se tedy jedná o text, než o klasický obrázek (fotku).
Z výsledku již provedeného pokusu [14] mohu citovat, že na vzorku 20 obrázků, z nichž 10 byly klasické obrázky (fotky) a 10 text v grafické podobě, byly hodnoty entropie u všech textových obrázků v intervalu <0;3> (viz Obr. 4), 2 z 10 klasických obrázků měly hodnotu entropie v intervalu <2;3> a všechny zbývající klasické obrázky měly entropii v intervalu <6;8> (viz Obr. 5).
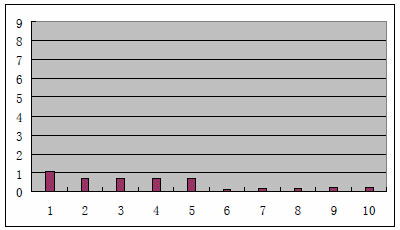
Obr. 5 – Hodnoty entropie pro textové obrázky [14]
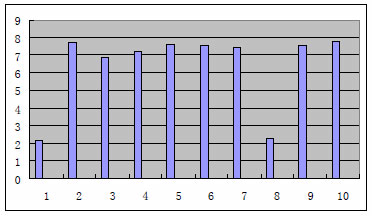
Obr. 4 – Hodnoty entropie pro klasické obrázky [14]
Určíme-li z testovaného vzorku hranici pro dělení obrázků mezi klasické a textové hodnotu 3, jelikož jen jediný textový obrázek měl hodnotu entropie větší než 2, můžeme konstatovat, že metoda má 100% spolehlivost v případě rozeznání textu v grafické podobě a 80% spolehlivost v případě rozeznávání klasických obrázků. Je zřejmé, že v případě netextových obrázků, kde se pravidelně opakují hodnoty světlosti pixelů (např. grafy, vektorová grafika apod.), bude metoda méně spolehlivá.
Nástroje pro získávání informací z webových portálů
V závěrečné části se chci věnovat popisu a srovnání dostupných nástrojů, které lze k sbírání informací z webových portálů použít. V praxi se často kombinují výše zmíněné přístupy, kdy prvotní sběr informací provede typizovaný nástroj, který sesbírá a roztřídí nejčastěji se vyskytující formáty dat, následuje individuálně vytvoření nástroj pro kategorizaci méně běžných dat nebo speciálního členění získaných dat – viz příklad s dělením obrázků podle druhu grafiky, ale téměř nikdy se nevyhneme lidské práci při rozdělení zbytku, který nemohl být automatizovaně zpracován pro jeho těžkou identifikaci na základě pravidel.
Screen Scraper
Velmi zajímavým nástrojem pro čtení obsahu internetových stránek, jejich kategorizaci a ukládání je software americké firmy ekiwi Screen Scraper. Zajímavostí je, že tuto společnost založil její vlastník až po úspěchu Screen Scraperu, jehož první verzi naprogramoval sám po večerech a víkendech. V současnosti je tento software využíván mnoha předními světovými technologickými firmami jako Microsoft, Cisco, Seagate, mnoha nákupními srovnávacími portály a společnost Oracle ho začlenila do svého podnikového řešení pro vyhledávání informací na webu Oracle Secure Enterprise Search.
Hlavními výhodami tohoto software jsou:
- „procházení skrz odkazy,
- vyplňování a potvrzování formulářů,
- interakce se stránkami výsledků hledání (dokáže na webovém portálu vyhledávat pomocí jeho vyhledávače),
- stahuje dokumenty (pdf, word, obrázky)“ [16]
Co z něj však dělá silný nástroj (mimochodem za celkem příznivou cenu) je konektivita. A to jak ve směru dovnitř, tak i obráceně. Funkce tohoto software lze využívat prakticky z jakéhokoliv prostředí, ať Windows nebo Linux – konektory existují z Javy, Php, .Net, Perlu, Ruby a mnoha dalších vývojových platforem a prostředí. Stejně tak získaná data lze kromě běžného uložení na disk v mnoha formátech také ukládat do různých typů databází, ale i publikovat rovnou do RSS feedů. Mimo to obsahuje i vestavěný interpreter různých skriptovacích jazyků (JScript, JavaScript, VBScript, Python), kterým lze vytvářet dávkové úlohy a začleňovat do nich vlastní business logiku.
Web Extractor
Web Extractor je na rozdíl od předchozího software zaměřen více na velká podniková řešení. Nejedná se jen o software pro získávání dat z webových stránek, ale jeho výrobce k němu přidružuje i další služby a především obsahuje předpřipravená pravidla pro získávání dat z určitých oblastí.
Dle internetových stránek jeho výrobce, německé společnosti 30Digits jsou hlavními výhodami jejich produktu:
- „rozšíření o kategorizaci informací dle zaměření,
- strukturování a normalizace pro analýzu a zpracování.“ [17]
Výhoda tohoto řešení je zřejmá pro firmy působící v oblastech, kde je sice velká potřeba sbírání dat z internetových portálů, ale výsledky se nenabízejí přímo zákazníkům, ale spíše se používají pro vlastní potřebu v konkurenčním boji. Společnost 30Digits svým produktem oslovuje téměř výhradně jen firemní zákazníky. Náklady na provoz jsou také výrazně vyšší, každý zákazník dostává individuální kalkulaci. Nejčastějšími oblastmi, kde se tento produkt nasazuje, jsou energetika, realitní trh, hoteliérství a pohostinství a sociální sítě. Z doprovodných služeb je nejčastěji využívána Business Intelligence, což lze vzhledem k povaze zákazníků a oblastí nasazení předpokládat.
Závěr
V předešlém textu jsem popsal základní technické metody sběru informací z internetových portálů, stránek a dokumentů. Druhá část obsahuje názorný příklad kategorizace získaných dat a v neposlední řadě jsem chtěl alespoň stručně prezentovat oblíbený nástroj pro sbírání informací Screen Scraper, vhodný pro použití ve small business sféře, ale i jeho enterprise konkurenta s mnoha doplňkovými službami. V závěru bych rád nastínil alespoň několik způsobů, jak naopak webové stránky před prací automatizovaných sběračů dat ochránit.
Způsoby blokování automatických sběračů dat
Pokud se aplikace chová slušně (viz politika zdvořilosti), lze ji zastavit záznamem v Robots.txt. Lze samozřejmě blokovat IP adresu, odkud požadavky přichází, ale to blokuje i ostatní legitimní provoz z této adresy. Jinou možností je monitorovat provoz na webu. Automatické programy mají monotónní chování a provádějí výrazně více požadavků za stejnou dobu než živý návštěvník, i když některé se mohou maskovat i tímto chováním. Asi nejznámější technikou k blokování tzv. „botů“ je použití CAPTCHA. Jedná se o slovo nebo krátký text zobrazený v grafické podobě tak, že jej nelze automaticky přečíst a jen na základě lidského úsudku je možné určit, co je v něm napsáno. Tento text je poté potřeba zadat do formuláře, aby šlo pokračovat v prohlížení daného webu. Existují i komerční služby, které chrání weby před neautorizovaným automatickým přístupem a některé weby zase využívají CSS nebo JavaScript, aby robotům alespoň ztížily práci.
Dá se očekávat, že ačkoliv je v současné době čtení obsah internetových portálů na vzestupu, do budoucna bude spíše důležité data na stránkách chránit a
zabezpečit tak zachování jejich unikátnosti.
Použitá literatura
[1] WIKIPEDIA, The free encyclopedia, cit. 10.11. 2011, dostupné z www http://en.wikipedia.org/wiki/Price_comparison_service#Technology
[2] WIKIPEDIA, The free encyclopedia, cit. 10.11. 2011, dostupné z www http://en.wikipedia.org/wiki/Web_crawler
[3] Edwards, J., McCurley, K. S., and Tomlin, J. A. “An adaptive model for optimizing performance of an incremental web crawler”, 2001 In Proceedings of the Tenth Conference on World Wide Web, str. 106–113
[4] Gulli, A.; Signorini, A. "The indexable web is more than 11.5 billion pages", 2005 Special interest tracks and posters of the 14th international conference on World Wide Web
[5] Jirovský T., Teorie grafů, cit. 11.11. 2011, dostupné z www http://teorie-grafu.cz/vybrane-problemy/nejkratsi-cesta.php
[6] Cho, Junghoo; Hector Garcia-Molina, "Synchronizing a database to improve freshness". 2000 Proceedings of the 2000 ACM SIGMOD international conference on Management of data, 117–128, dostupné z wwwhttp://dl.acm.org/citation.cfm?doid=342009.335391
[7] WIKIPEDIA, The free encyclopedia, cit. 10.11. 2011, dostupné z www http://en.wikipedia.org/wiki/Web_crawler
[8] Koster, M., Robots in the web: threat or treat? 1995 ConneXions
[9] Coulouris G., Dollimore J., Kindberg T., Blair G., Distributed Systems Concepts and Designs, Fifth Edition, str. 740, 2011 AddisonWesley, ISBN 0-13-214301-1
[10] Cho J., Garcia-Molina H. Parallel Crawlers, 2002 University of California, Los Angeles, Stanford University, dostupné z wwwhttp://www2002.org/CDROM/refereed/108/
[11] WIKIPEDIA, The free encyclopedia, cit. 14.11. 2011, dostupné z www http://en.wikipedia.org/wiki/Crowdsourcing
[12] McNichol, Tom, "The Wales Rules for Web 2.0", 2007 Business 2.0. cit. 14.11.2011, dostupné z wwwhttp://money.cnn.com/galleries/2007/biz2/0702/gallery.wikia_rules.biz2/index.html
[13] WIKIPEDIA, The free encyclopedia, cit. 14.11. 2011, dostupné z www http://en.wikipedia.org/wiki/Entropy_%28information_theory%29
[14] Web-mining and data analysis, 2006 HØGSKOLEN I AGDER, Agder University College, Faculty of Engineering and Science, dostupné z www http://www.eiao.net/webmining/previousprojects/reportgroup5.pdf
[15] MathLab documentace, MathWorks Inc., citováno 14.11.2011, dostupné z www http://www.mathworks.com/help/toolbox/images/ref/entropy.html
[16] Screen Scraper, ekiwi LLC, citováno 15.11.2011, dostupné z www http://www.screen-scraper.com
[17] Web Extractor, 30Digits GmbH, citováno 15.11.2011, dostupné z www http://www.30digits.com/web-extractor-nav/en